movienetdata: A data package for character interactions in popular films
Table of Contents
I recently released the data I collected during my PhD research as a data package for R. The main reasons I did this are:
Sharing
One of the most common questions I get when chatting to people at conferences etc. is whether my data is publicly available. I assume this means that people would be interested in taking a look at the data, analysing it, playing around with it and such.
The dataset was generated to answer questions about the narrative marginalisation of women in popular cinema. However, there are a number of reasons why somebody might want to use it beyond this purpose:
- It is an ideal dataset for exploring character networks in all their complexity - each film in the dataset comes with both an event list, which can be used for constructing dynamic network representations of the narratives, and an adjacency matrix derived from this event list, which can be used for static network representations. The event list also indexes each interaction by scene, allowing for the interaction data to be grouped into story chunks.
- The dataset offers useful teaching data for illustrating basic network analysis ideas using familiar, easy to grasp examples of networks.
- I'm sure there are all kinds of interesting questions about the films that the data can help to answer that I didn't think to ask.
Making my life easier
I plan on sharing other aspects of my character network analysis work, and releasing the data this way allows me to separate out the data from the core functionality of the various tools and functions that I work with. This is useful as it helps me to ensure that they make sense independently of the particular data with which I have been using them to work.
Finally, I wanted some hands-on experience with R package development, and data packages offer a great way to learn the basics of package structure and documentation.
How to use the data
In R
If you use R, you can install the package using any package manager that can install from git repositories:
# e.g. using {remotes}:
remotes::install_git("https://codeberg.org/pjphd/movienetdata.git")
# or using {pak}:
pak::pkg_install("git::https://codeberg.org/pjphd/movienetdata.git")
Then, load the package:
library(movienetdata)
You can browse the complete list of different films in the dataset using data(package = "movienetdata"):
And load a specific film into the workspace using e.g. data("mcu01_ironman", "movienetdata").
Each film is stored as a list containing three elements:
- The event list. Each row contains information on a line of dialogue,
with columns corresponding to
eventID,sceneID,speakerID, and dummy variables for each recipient. - The node list. Rows correspond to named speaking characters, with
columns corresponding to variables for ID, name, total lines spoken
(
nlines), total times spoken to (linesin), and gender. Note that some films in the dataset might have additional or different variables included. - The adjacency matrix. This is derived from the event list through aggregation and can be useful for static purposes such as visualising the network as a sociogram.
Access specific elements by name or by indexing the list:
# Get the nodes by name
mcu01_ironman$node_list
# Get the nodes by indexing
mcu01_ironman[[2]]
Example:
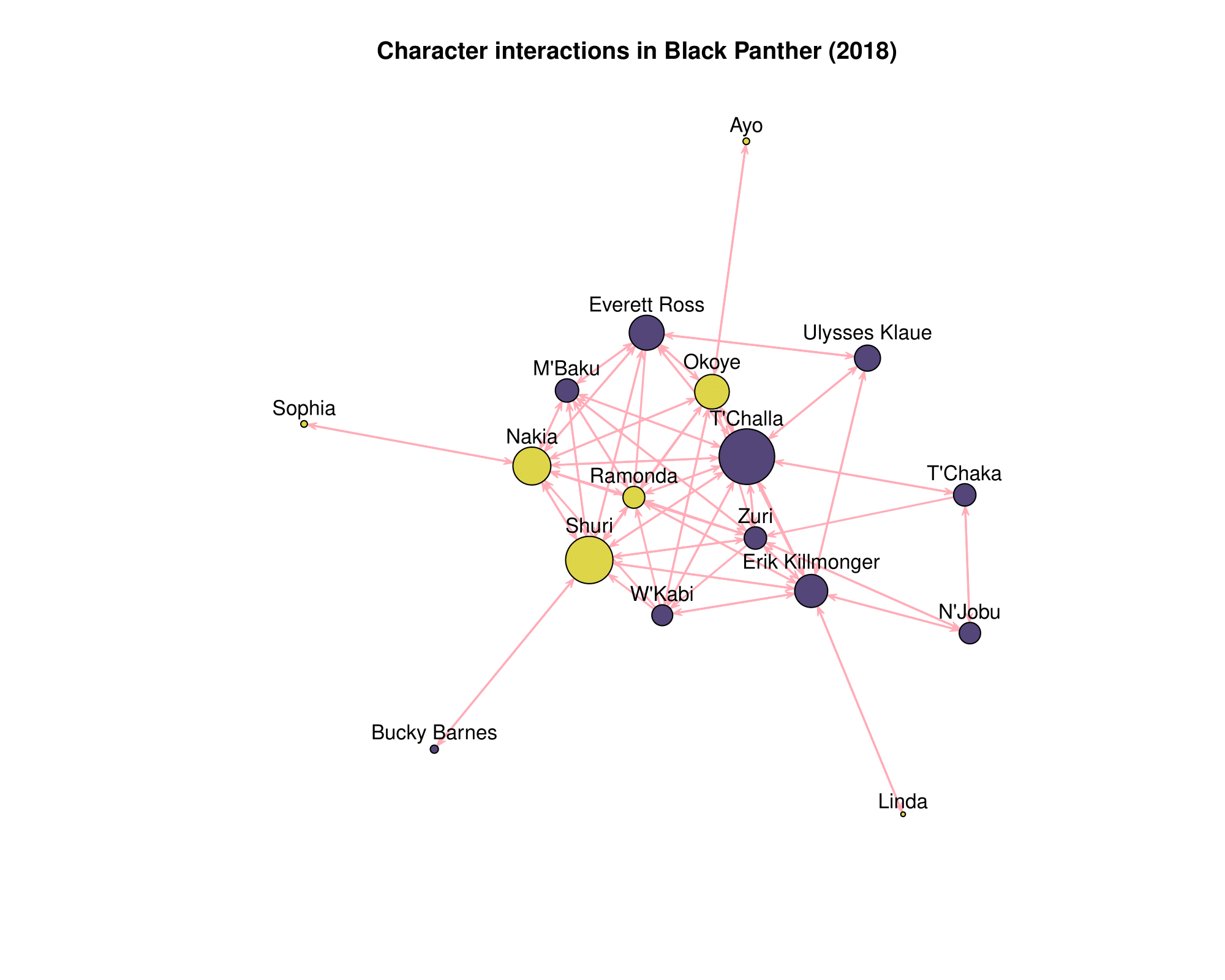
If you just want to create a quick network diagram for the film Black Panther, you can do something like this:
black_panther <- movienetdata::mcu18_blackpanther
# install.packages("network")
library(network)
# Create network object from adjacency matrix
bp_net <- network(black_panther$adjacency)
# Plot the network
plot(bp_net, label = black_panther[[2]]$char_name,
edge.col = "lightpink1",
vertex.cex = sqrt(black_panther[[2]]$nlines)/3,
label.pos = 3, arrowhead.cex = 0.7,
vertex.col = ifelse(black_panther[[2]]$char_female == 1,
"#ded649", "#55467a"),
main = "Character interactions in Black Panther (2018)")
Not in R
If you're not an R user, you can still access the raw data from the package source repository. In the data-raw folder you will find the CSV files for each film's event list and node list.
This post was edited to update the various references to the package source repository, which is now hosted on Codeberg.